
What is Voxtral?
Voxtral represents a significant advancement in open-source speech understanding technology. Developed by Mistral AI, this model goes far beyond simple transcription to offer comprehensive audio analysis capabilities. Released under the permissive Apache 2 license, Voxtral empowers developers and organizations to integrate sophisticated speech processing into their applications without licensing restrictions.
The model comes in two distinct versions optimized for different use cases. The 24-billion parameter version delivers production-ready performance for enterprise applications, while the 3-billion parameter variant enables local deployment on edge devices with constrained resources. Both versions maintain the same core capabilities while adapting to different computational environments.
Built on the foundation of Mistral Small 3.1, Voxtral inherits robust text understanding capabilities while adding specialized speech processing features. This architecture allows the model to understand context, answer questions about audio content, and perform complex analysis tasks that traditional speech recognition systems cannot handle.
Core Capabilities
Long-Form Audio Processing
Process audio content up to 30-40 minutes in length without losing context. Perfect for meetings, lectures, podcasts, and extended conversations.
Built-in Question Answering
Ask questions about audio content and receive accurate, contextual answers. Extract key information without manual review.
Automatic Summarization
Generate concise summaries of audio content, identifying main themes, key points, and important details automatically.
Multilingual Support
Process audio in multiple languages with automatic language detection. Supports Spanish, French, Portuguese, Hindi, German, Dutch, Italian, and more.
Function Calling
Convert natural language voice commands into structured function calls, enabling voice-controlled applications and workflows.
High Accuracy Transcription
Achieve competitive transcription accuracy that bridges the gap between open-source solutions and proprietary APIs.
Available Model Versions
Voxtral 24B
Production Version
- 24 billion parameters
- Enterprise-grade performance
- Server deployment optimized
- Maximum accuracy
Recommended for production applications requiring the highest quality speech understanding.
Voxtral 3B
Edge Version
- 3 billion parameters
- Local deployment ready
- Edge device compatible
- Reduced resource requirements
Perfect for mobile applications, IoT devices, and scenarios requiring local processing.
Technical Specifications
System Requirements
- • Python 3.8 or higher
- • GPU recommended for optimal performance
- • 10GB+ storage for model files
- • Internet connection for initial setup
- • CUDA support for GPU acceleration
Model Details
- • Architecture: Transformer-based
- • License: Apache 2.0
- • Base model: Mistral Small 3.1
- • Context length: Up to 40 minutes audio
- • Supported formats: WAV, MP3, FLAC
Real-World Applications
Meeting Transcription
Automatically transcribe and summarize business meetings, extracting action items and key decisions.
Content Creation
Transform podcast episodes and video content into searchable text and generate episode summaries.
Voice Assistants
Build intelligent voice interfaces that understand complex commands and provide contextual responses.
Educational Tools
Create accessible learning materials by transcribing lectures and generating study summaries.
Customer Support
Analyze customer calls for quality assurance and extract insights for service improvement.
Research & Analysis
Process interview recordings and focus groups for qualitative research and data analysis.
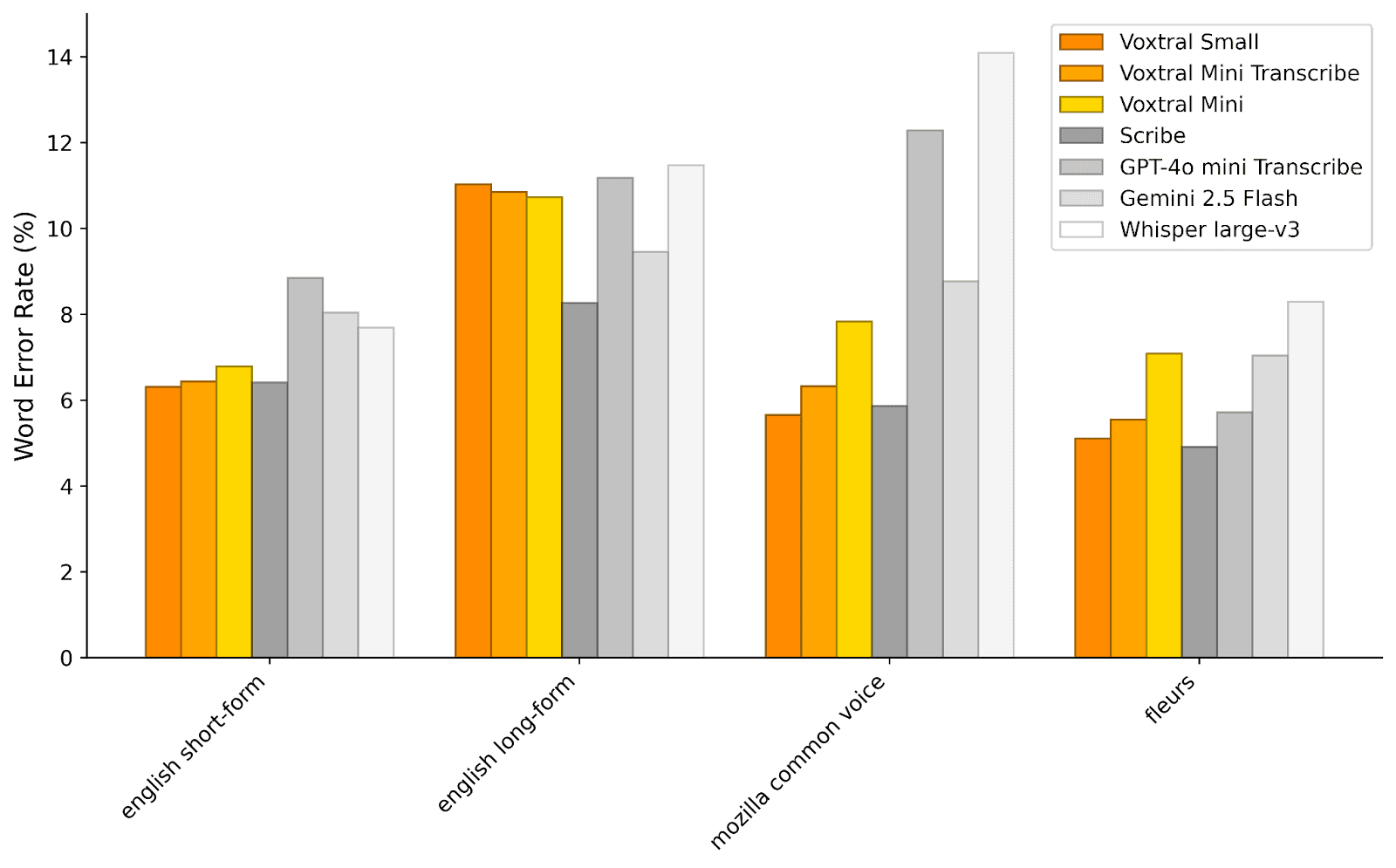
Performance Benchmarks
Voxtral demonstrates competitive performance across multiple evaluation metrics, positioning it as a viable alternative to proprietary solutions. The model excels particularly in multilingual scenarios and complex audio understanding tasks.
Transcription Accuracy
Supported Languages
Maximum Audio Length
Getting Started with Voxtral
Quick Installation
# Install with UV package manager
uv pip install vllm
# Serve the model locally
vllm serve mistralai/voxtral-3b
# Or use the 24B version for production
vllm serve mistralai/voxtral-24bBasic Usage Example
from mistral_common import ChatCompletionRequest
from mistral_inference import generate_completion
# Initialize client
client = VoxtralClient("http://localhost:8000")
# Process audio file
result = client.transcribe("audio_file.wav")
print(result.transcript)
# Ask questions about the audio
response = client.query("What are the main topics discussed?")
print(response.answer)Community & Support
Voxtral benefits from an active open-source community of developers, researchers, and organizations working together to advance speech understanding technology. The Apache 2 license ensures that improvements and adaptations can be shared freely.
Resources
- • Model documentation and API reference
- • Tutorial notebooks and code examples
- • Performance optimization guides
- • Deployment best practices
Contributing
- • Report issues and suggest improvements
- • Contribute to model documentation
- • Share use cases and applications
- • Help with multilingual testing